Die Stimme ist das zentrale Element der meisten Songs und spielt daher auch beim Mixing oft die Hauptrolle. Die meisten Mixing-Engineers haben ihren eigenen Workflow und bevorzugen bestimmte Plugins. In diesem Beitrag zeige ich dir, wie ich beim Stimme bearbeiten Schritt für Schritt vorgehe. Diese Vorgehensweise kannst du mit jeder DAW und deinen eigenen Plugins umsetzen.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen
Stimme bearbeiten in 5 Schritten:
Schritt 1: Dynamik einschränken
Bei Gesangs-Aufnahmen kommt es aufgrund der natürlichen Dynamik des Sängers/der Sängerin oft zu Lautstärke-Schwankungen in der Audio-Spur. Diese sind mal stärker und mal weniger stark ausgeprägt, je nach Song und Sänger/in. Beim Stimme bearbeiten ist es wichtig, diese Schwankungen zu minimieren. Die einzelnen Passagen sollen ausgewogen im Mix erscheinen und alle Worte müssen deutlich zu verstehen sein. Vor allem an Wort- oder Satzenden kommt es vor, dass Stimmen leiser werden. Bevor du jetzt einen Kompressor in deine Effekt-Kette lädst, macht es Sinn erst einmal die Lautsärke Pre-Fx, also vor dem Effektkanal grob anzugleichen.
Dies kannst du mithilfe einer Lautstärke-Automation erledigen, die du mit der Maus oder einem Controller einzeichnest. Damit kannst du wunderbar die Lautstärke bestimmter Passagen oder einzelner Wortsilben anpassen. Alternativ kannst du auch ein Plugin, wie zum Beispiel den Vocal-Rider dafür verwenden. Ich würde das manuelle Automatisieren jedoch immer vorziehen, da du dabei einfach viel genauer und nach deinen Vorstellungen arbeiten kannst.
Schritt 2: Störfrequenzen reduzieren
Beim Stimme bearbeiten gibt es im Prinzip 3 Störfrequenzbereiche, die du beachten solltest:
- Rauschen: Du solltest natürlich schon beim Recording darauf achten, dass du kein Rauschen oder Hintergrundgeräusche (z.B Pc-Lüfter) auf der Aufnahme hast. Falls es doch dazu gekommen ist und du es erst beim Mixing bemerkst, kannst du mit einem Noise-Gate oder manuell mit einem Equalizer die störenden Frequenzen herausfiltern.
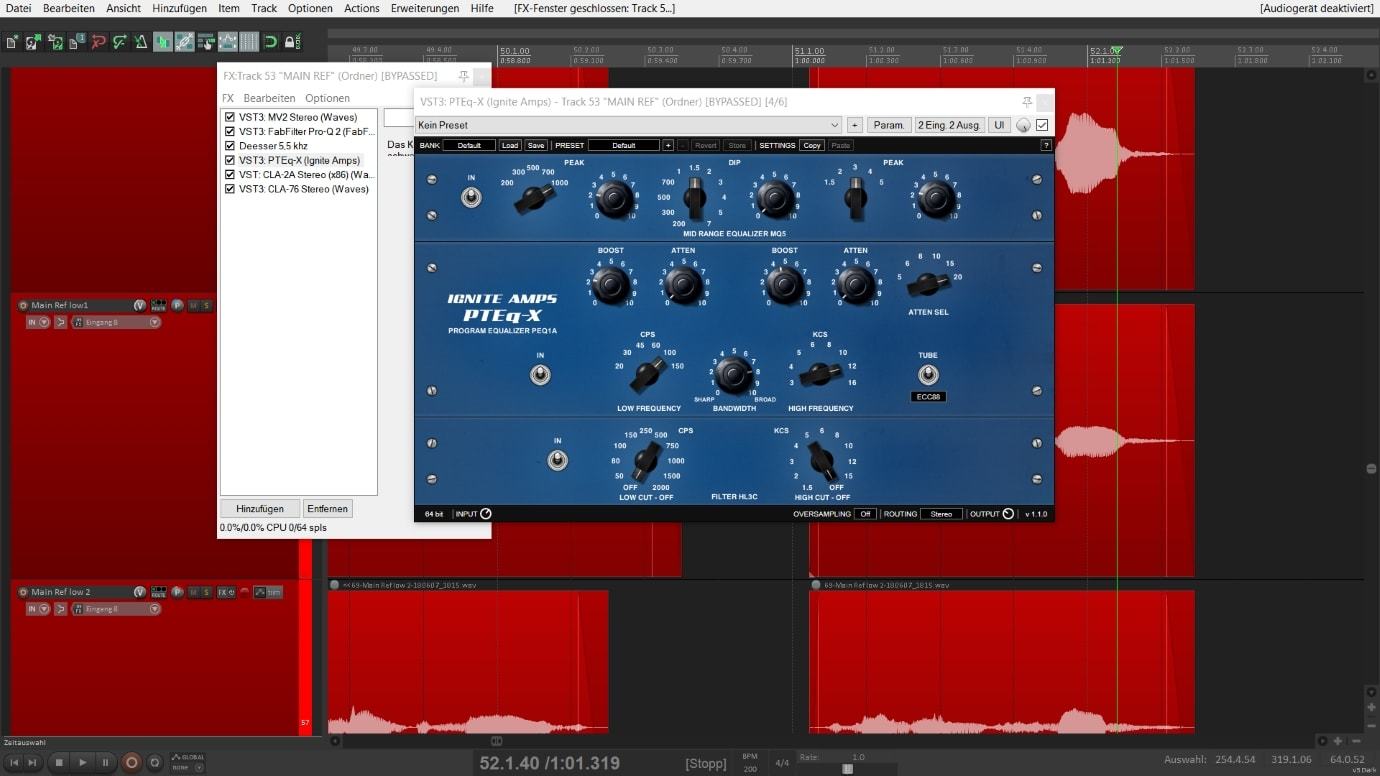
- Resonanzen: Im Homestudio hat man nicht immer eine perfekte Raumakustik. Daher regt deine Stimme vorallem im Bassbereich (50 bis 300Hz) Raummoden zum Schwingen an. Bestimmte tiefe Frequenzen werden vom Mikrofon unnatürlich laut aufgenommen und deine Stimme klingt dumpf und basslastig. Um dies zu beheben kannst du mit einem Equalizer genau diese Frequenzbereiche um einige Dezibel reduzieren. Die meisten Equalizer zeigen dir beim Abspielen die Frequenzkurve deiner Stimme an. So kannst du die lauteren Wellenberge im Bassbereich sehen und leicht herausziehen. Du wirst merken, dass deine Stimme dadurch deutlich präsenter/heller wird. Manchmal kommt es auch im Mittenbereich zu Resonanzen, die einen nasalen Stimmanteil oder einen nervenden Dröhnklang erzeugen. Diese solltest du in diesem Schritt ebenfalls reduzieren.
- S-Laute: Unnatürlich scharfe S- und T-Laute gilt es beim Stimme bearbeiten ebenfalls zu entfernen. Mit einem Frequenz-Analyzer kannst du herausfinden in welchem Bereich die S-Laute bei deiner Stimme die meiste Energie haben. Dieser liegt meistens zwischen 4-7 khz. Zum reduzieren von scharfen S- und T-Lauten eignen sich De-Esser oder Multiband-Kompressoren. Im Plugin kannst du dann den ungefähren Frequenzbereich einstellen und mit dem Threshold (Schwellenwert) regeln, ab welcher Lautstärke/wie stark die S-Laute reduziert werden sollen.
Schritt 3: Signal färben
Nachdem du dein Signal von störenden Frequenzanteilen befreit hast, kannst du im Dritten Schritt geeignete Frequenzen hinzugeben. Die Stimme soll klar und präsent im Mix erscheinen und etwas mehr Charakter bekommen. Besonders eignen sich dafür Equalizer mit einer analogen Schaltungs-Simulation, du kannst aber auch deinen Standard Multiband-EQ verwenden. Es geht darum, in den Mitten und Höhen geeignete Frequenzen zu boosten. Im Mittenbereich kannst du ruhig ein paar schmalbandige Anhebungen vornehmen, damit die Stimme etwas mehr Kante und Charakter bekommt. Für die Höhen funktioniert eine breitbandige Anhebung meistens am Besten. Bei Bedarf kannst du auch eine leichte breitbandige Anhebung im oberen Bassbereich (250-650Hz) vornehmen um dem Gesang etwas mehr Gewicht zu verleihen. In diesem Schritt kannst du deiner Stimme auch mit einer Tape- oder Röhren-Simulation etwas Sättigung hinzufügen.
Schritt 4: Kompression
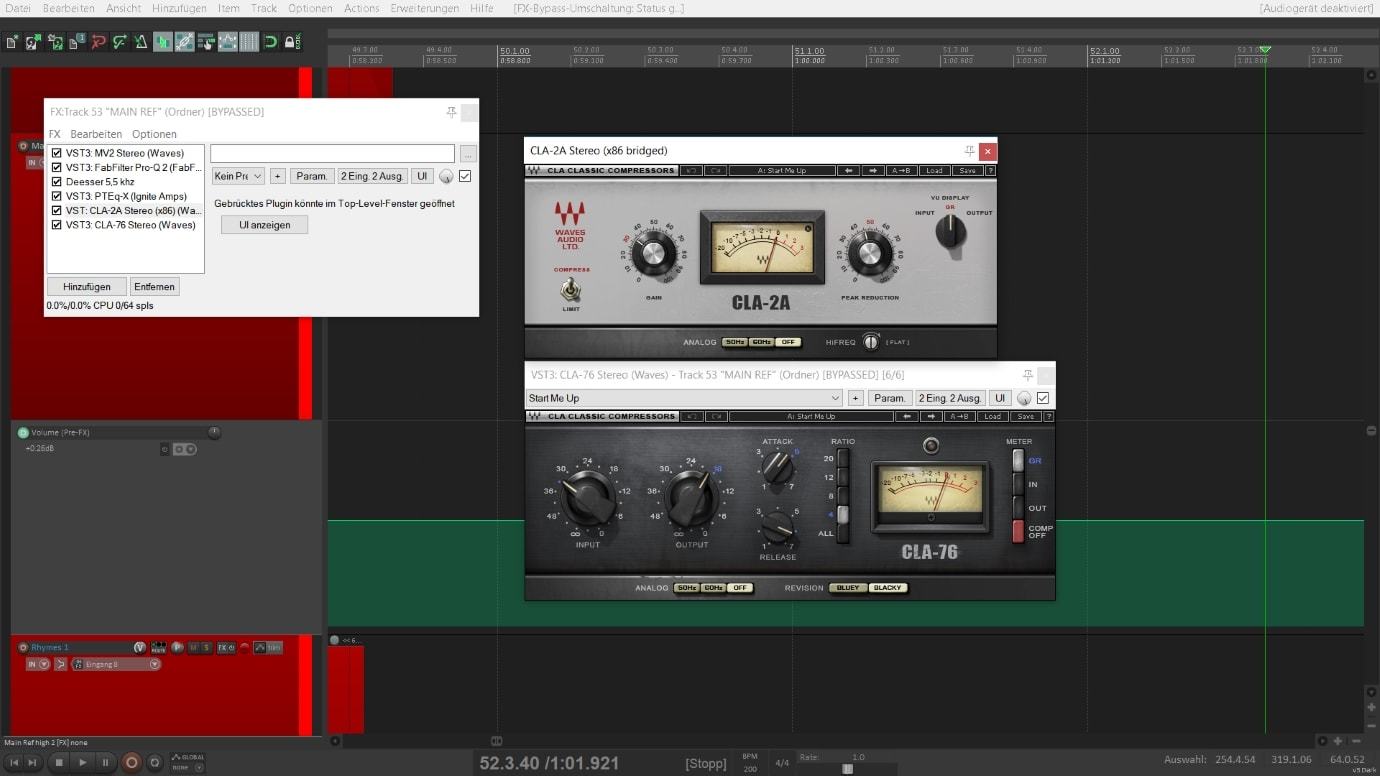
Die Lautstärke der Stimme ist grob ausgeglichen, du hast Störfrequenzen reduziert und dem Signal etwas Farbe/Charakter hinzugefügt. Der Gesang ist aber immer noch nicht so richtig weit vorne im Mix und Dynamikschwankungen sind auch noch nicht ausgeglichen. Es braucht mehr Kontrolle. Zeit für den Einsatz von Kompression. Beim Abmischen von Gesang verwende ich meistens zwei Kompressoren hintereinander. Damit kann ich laute Ausreißer und unausgeglichene Gesangspassagen auf ein konstantes Dynamiklevel bringen. Zwei leicht eingestellte Kompressoren arbeiten subtiler und effizienter als ein stark eingestellter Kompressor (in Bezug auf Gain-Reduction).
Als ersten Kompressor in der Kette nach dem färbenden Equalizer verwende ich einen langsamer arbeitenden Kompressor (Optical-Kompressor) wie den CLA-2A. Dieser arbeitet relativ unauffällig, heißt er kann das Signal stark komprimieren ohne auffälligen Pump-Effekt und sorgt dabei für eine ausgeglichene Dynamikstruktur. Eine tolle Eigenschaft dieses Kompressors: Er holt die Stimme im Mix nach vorne. Der zweite Kompressor als letztes Plugin in der Kette hat die Aufgabe, die Stimme final zu verdichten. Er soll etwas zügiger arbeiten (kürzere Attack-, mittlere Releasezeit) um auch schnell durchkommende Peaks abfangen zu können. Dafür eignen sich Kompressoren wie der klassische „1176“ bzw. ähnliche Modelle. Wenn es deiner Stimme nach diesen Bearbeitungsschritten immer noch etwas an Durchsetzungskraft fehlt, kannst du sie mit einem leicht eingestellten Limiter hinten dran noch etwas nach vorne bringen/verdichten.
Schritt 5: Send-Effekte
Die Plugin-Kette ist vollendet. Jetzt kannst du der Stimme mithilfe von Send-Effekten noch Reverb/Raum und Delay hinzufügen.
Einen Send-Effekt erstellen:
- Neuen Track hinzufügen
- Einen Reverb-Effekt/Raumsimulation o.ä in den Effektkanal des Tracks laden
- Den Ausgang deines Vocal-Tracks auf den erstellten Track mit dem Effekt routen.
- Mit der Lautstärkeregelung von Vocal-Track zu Send-Effekt (im Routing-Bereich) die Intensität des Effekts bestimmen
Du kannst im Prinzip jedes beliebige Reverb/Raumsimulations-Plugin für die Tiefenstaffelung verwenden. Um eine schöne räumliche Wirkung zu erzielen, verwende ich je nach Stimme und Song oft mehrere Send-Effekte. Zum Beispiel einen kleinen Raum für die Illusion von schnellen Reflektionsimpulsen, ein Slap-Delay für etwas mehr räumliche Bewegung und 2 verschiedene größere Räume/Plates für etwas längere Hallfahnen und mehr Tiefe.
